
Similr.ai uses OpenAI's state of the art Large Language Models (LLMs) which contains biases inherit in the embeddings. Results are dependent on the questions which were created by OpenAI's GPT4 and tend to contain biases themselves. Open AI Limitations & Risks
All famous people are simulated using OpenAI's GPT4 to answer questions. (300-600 questions per person) Their results are dependent on GPT4's knowledge of the person and will inherently contain any biases in that knowledge.
Questions/Comments/Suggestions - use our feedback form. (login required)
Thank you for taking the time to check out Similr.ai. Hope you enjoy it as much as we've enjoyed building it!
How Similr.ai Works
The Quick Non-Technical Answer
Everytime you make a choice the AI understands what that choice means. After making enough choices it has a solid understanding of the entirety of all of your choices. This understanding can then be used to tell you how much of certain "things" are in your choices.
The Quick Technical Answer
Similr.ai uses OpenAI's embeddings (text-embedding-ada-002) to create a "user embedding" which represents information from every choice the user made in answering this or that questions. This user embedding is the simple element wise average of all the choices. A choice is represented by the chosen option's embedding minus the not chosen option's embedding.
The user embedding can then be directly compared to any other text embedding. The more similar the embeddings the more of "that" the user had in their choices.
The Long Answer
I'm still surprised how well this works. (Then again almost a year later I continue to be amazed by GPT4!) I believe it works due to the incredible depth of knowledge that is represented in these embeddings. For example what does it mean when someone chooses Coke over Pepsi or Dog over Cat? We all probably have some mental concept in our heads but its hard to put into words. The difference embedding likely captures this meaning exceptionally well and then when you take all of these choices and average them you get a user embedding that is rich with meaning.
Testing On Famous People
Since it would be hard to find people to take this test and then know if the results were accurate, I decided to have GPT4 pretend to be the famous people and answer the questions as though it was the person. I also had it produce a percent probabilty that the user would choose that option. If the choice was close to 50% it was marked as a skip. It also produced an explanation for the choice. This allowed me to go through and spot check the decisions.
Here are some examples:
Barack Obama
Choice: 85% Left
Left Choice: Would you rather lead a team on a volunteer project with specific, impactful goals?
Right Choice: Would you rather engage in casual conversations at a local cafe's trivia night with a group of acquaintances?
Obama's history of community organization and leadership suggests a preference for leading a team on a project over casual socializing.Choice: 55% Left (Skip)
Left Choice: Exploring the depths of the ocean in 'Titanic's tragic love story.
Right Choice: Witnessing the whimsical and magical world of 'Harry Potter'.
Given Obama's varied tastes in cultural experiences, but with no explicit preference for fantasy, he might lean towards the historical and romantic aspects of 'Titanic'.Choice: 70% Left
Left Choice: Indulging in the rich and flavorful cuisine while touring Tokyo, Japan's sprawling metropolis.
Right Choice: Embarking on an adventurous hiking journey in Switzerland's scenic Alps mountains.
Considering his global diplomatic background and interest in history, Obama may find the cultural and culinary experiences of Tokyo more appealing.Barbie
Choice: 85% Left
Left Choice: Summer
Right Choice: Winter
Summer offers more opportunities for outdoor fashion and adventure, which Barbie would enjoy.Choice: 70% Right
Left Choice: The grand and sweeping classical compositions of the 18th century
Right Choice: The innovative electronic explorations in music of the 2020s
The innovative nature of 2020s electronic music fits with Barbie's forward-thinking and adaptive personality.Choice: 90% Left
Left Choice: Forging connections seeking meaning in relationships and altruism
Right Choice: Prioritizing self-reliance and detaching from social bonds
Barbie's commitment to inspiring children suggests a worldview that values connecting with others.Confidence Level On Famous People
I then took the average probabilty from GPT4 of all the questions per person to get an average confidence score for each famous person:
Least Confident
- Chrissy Hawkins (Stranger Things) - 64%
- Billy Hargrove (Stranger Things) - 66%
- Draco Malfoy (Harry Potter) - 66%
- Elaine Benes (Seinfeld) - 67%
- Marilyn Monroe - 68%
- Kanye West - 68%
- Justin Bieber - 69%
- Erica Sinclair (Stranger Things) - 69%
- Negan (The Walking Dead) - 69%
- Johnny Depp - 69%
- Tiger Woods - 69%
- Richard Nixon - 69%
- Jerry Seinfeld (Seinfeld) - 69%
- Leonardo DiCaprio - 69%
Most Confident
- Mahatma Gandhi - 82%
- Master Yoda - 79%
- Gandalf - 79%
- Santa Claus - 79%
- Mother Teresa - 79%
- Wonder Woman - 78%
- Lord Voldemort - 78%
- Sauron - 77%
- Batman - 77%
- Katniss Everdeen (Hunger Games) - 77%
- Atticus Finch - 77%
- Sherlock Holmes - 77%
- Homer Simpson - 77%
- Cersei Lannister - 77%
Similarity Score for User Similarity
Now that we have user embeddings we can compare two users to each other using cosine similarity. Cosine similarity gives you values between 1 and -1 with 1 being exactly the same and -1 exact opposites. To make them more human friendly I multiple by 100 and round to the nearest integer. This gives nice easy to compare values of 100 to -100.
The end result is you can now know exactly how similar:
- Donald Trump is to Jesus: -45
- Steve Jobs is to Elon Musk: 53
- Vecna (Stranger Things) is to Lord Voldemort (Harry Potter): 66
- Arya Stark (Game of Thrones) is to Max Mayfield (Stranger Things): 59
- Mother Teresa is to The Joker (Batman): -63
Check out Similarities Here (login required)
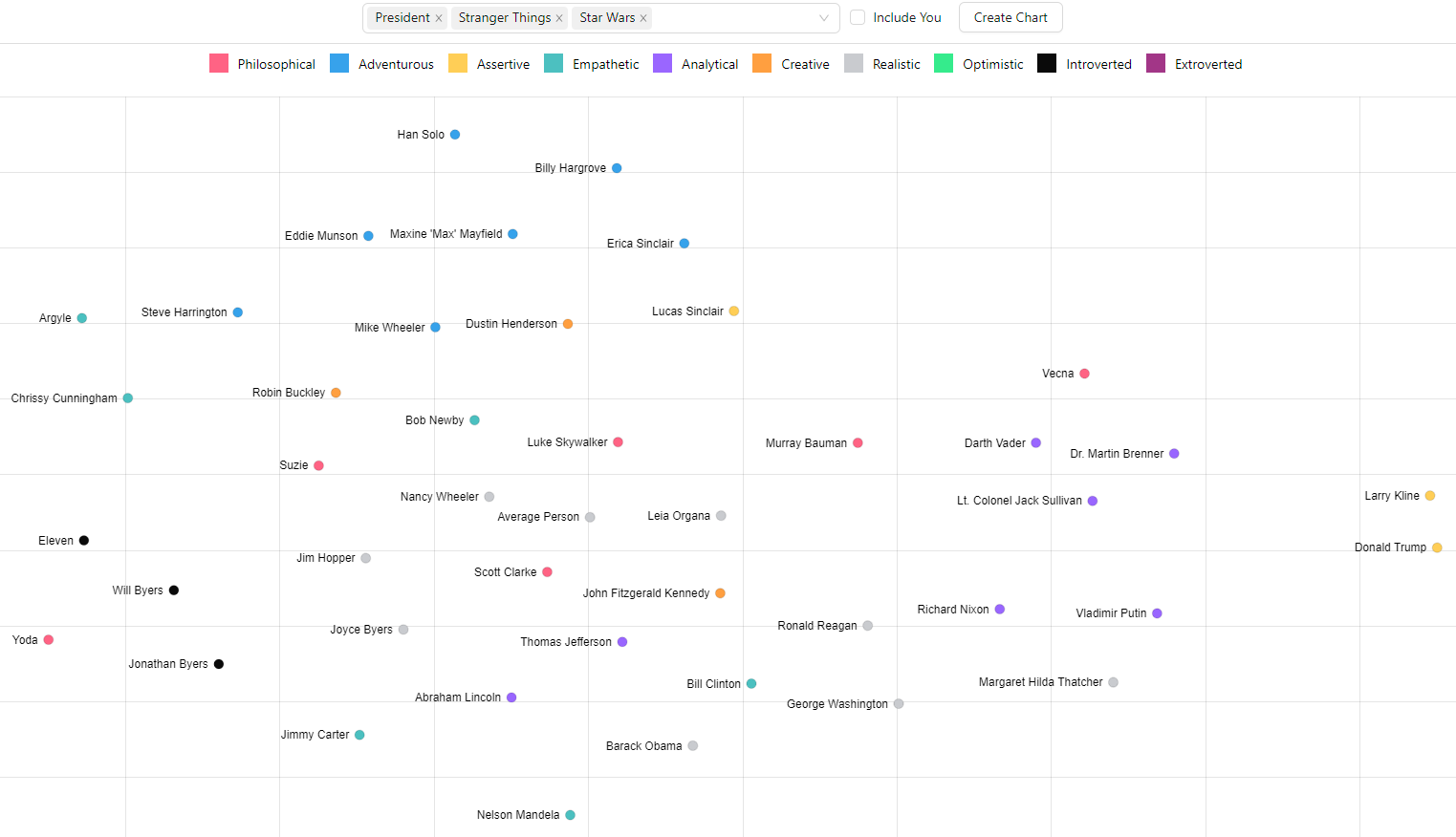
t-SNE for User Similarity
We can now use t-SNE to plot all the users on a 2D chart. t-SNE does an impressive job of compressing these 1,536 dimension vectors into 2 dimensions attempting to keep distances. The axis don't matter just how the people group and the distances between people. The dots are color coded for the top General Personality category.
All, Real People, Fictional Characters, Stanger Things, (Presidents, Stranger Things, Star Wars)
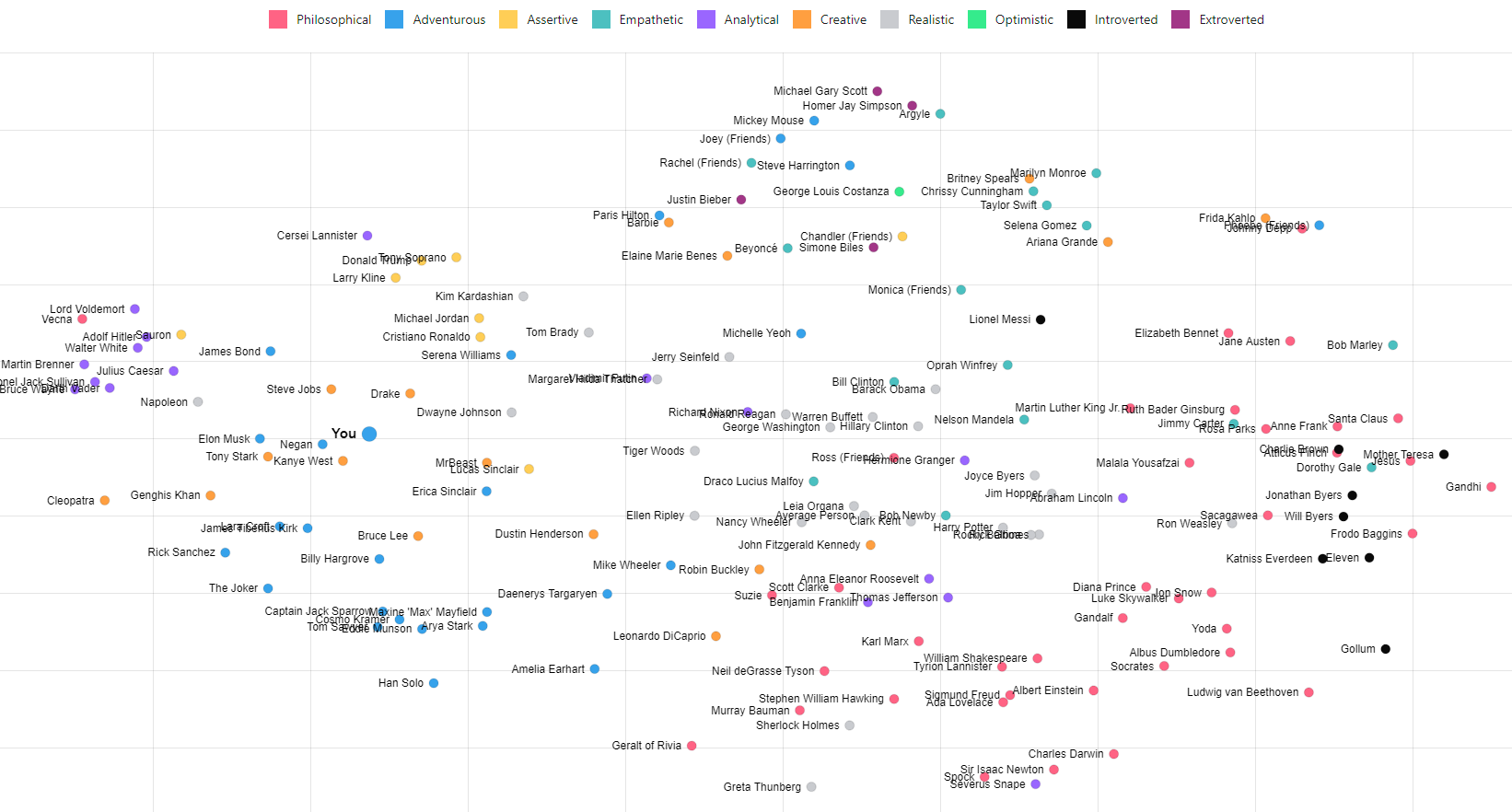
Preview
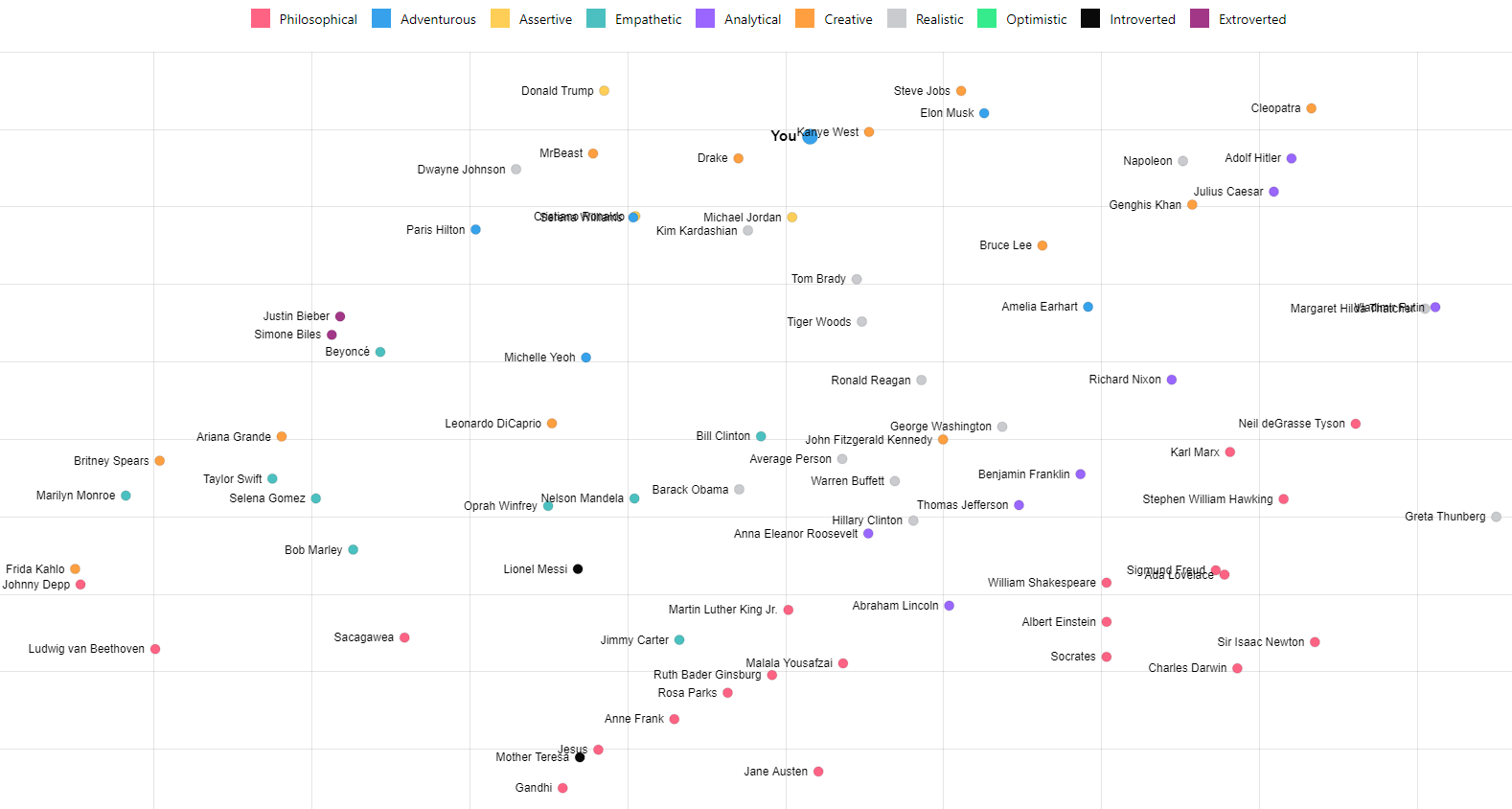
Preview
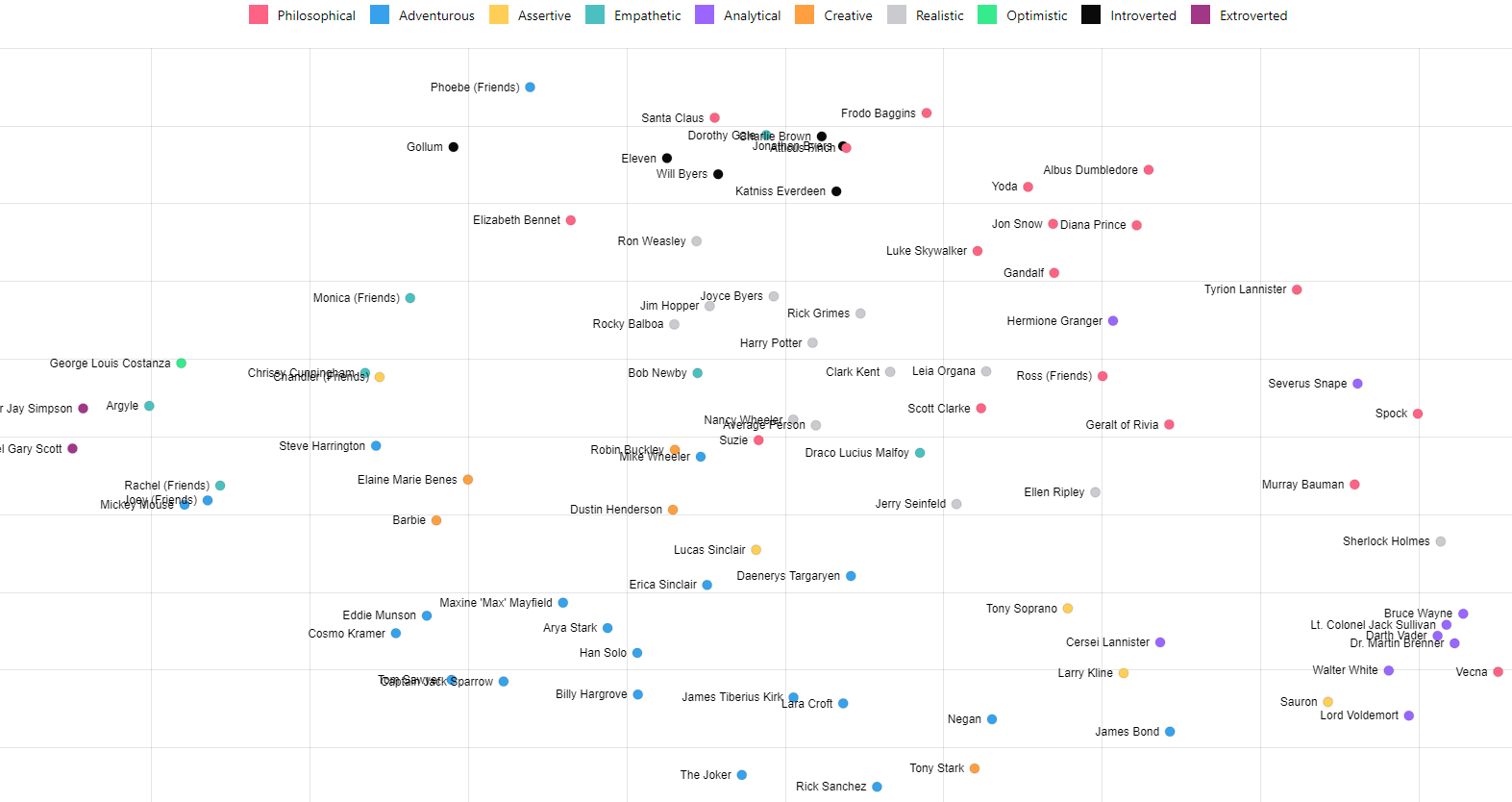
Preview
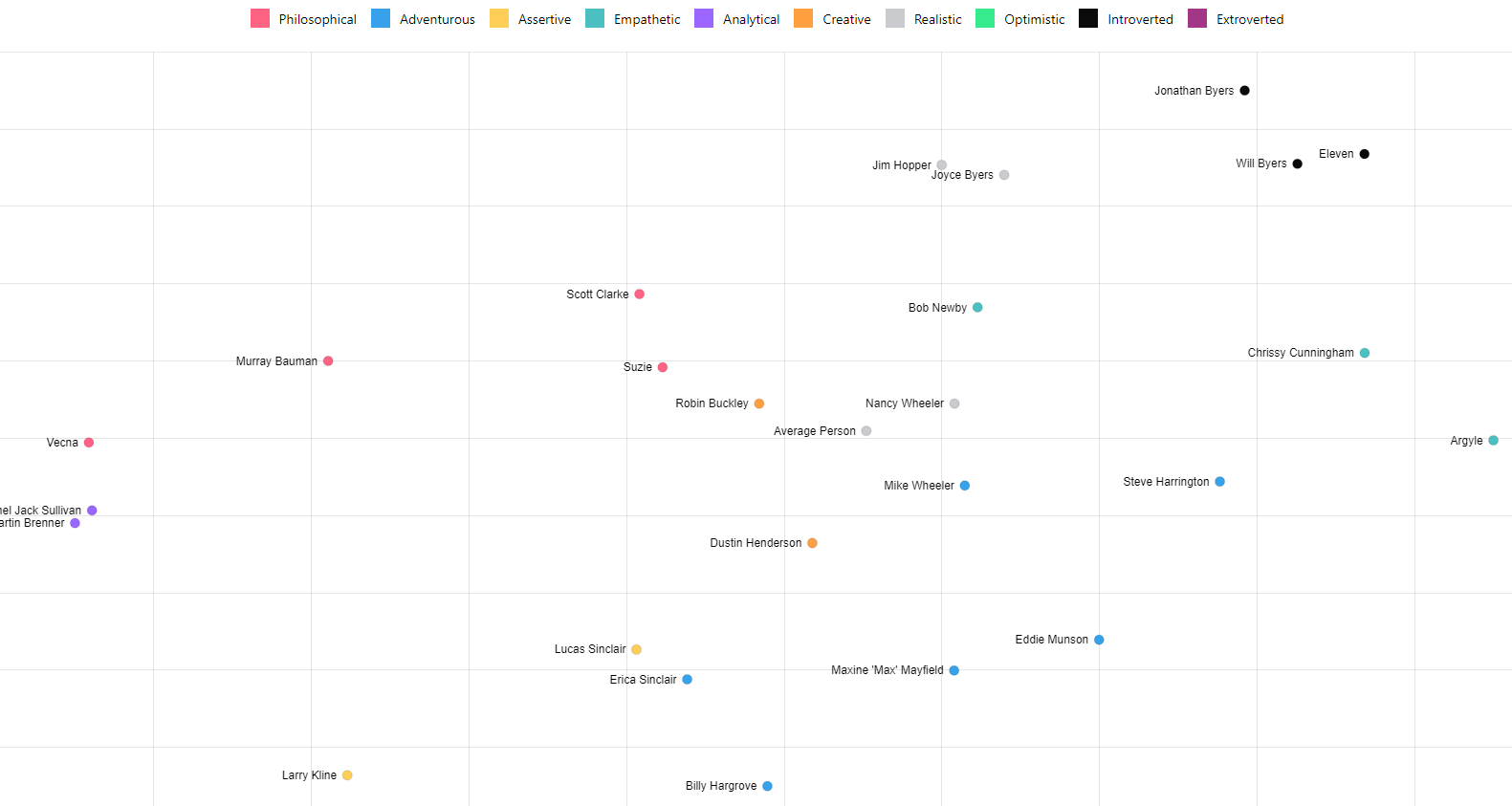
Preview
Preview
Try it out (login required)
Similarity Score for Text Embedding
Comparing the user embedding to any normal text embedding using cosine similarity tended to produce values in the 0.2 to -0.2 values. So to make them more human friendly, I would multiple by 1000 and round to the nearest integer. This gave nice easy to compare values of 200 to -200. Same as user similarity the higher the values the more similar the user embedding is to the text embedding.
Category Rankings
Now that we can generate a score for any text we can create categories and see how each item in the category ranks. Personality traits and careers worked well as many of the questions contain relevant information to these. I did general and more specific. You can do pretty much anything but the result quality depend heavily on the questions answered and the specific text that is embedded.
Elon Musk
- Technology: 182
- Engineering: 136
- Science and Research: 123
- Marketing and Communication: 81
- Business and Finance: 73
- Healthcare: 73
- Legal Profession: 51
- Education: 47
- Public Service: 24
- Arts and Entertainment: -2
Marilyn Monroe
- Arts and Entertainment: 113
- Education: 78
- Healthcare: 62
- Public Service: 45
- Legal Profession: 22
- Science and Research: 18
- Marketing and Communication: 4
- Business and Finance: -42
- Engineering: -55
- Technology: -56
Check out various categories and how famous people rank (login required)
Word Rankings
How about just simple words? I took the 10,000 most common words and created embeddings for each one and then looked at which words were highly ranked and which ones were lowly ranked for a famous person. It provides an interesting general feel for a person's personality.
Marilyn Monroe
Top Words
- romantic: 133
- romance: 117
- renaissance: 108
- literary: 105
- poetry: 102
- sympathy: 101
- loving: 101
- charming: 100
- artistic: 97
- charity: 96
Bottom Words
- engineer: -64
- gaming: -65
- stuck: -66
- hardware: -69
- battlefield: -72
- mechanical: -78
- survive: -79
- survival: -83
- tactics: -84
- hacker: -87
Elon Musk
Top Words
- innovation: 153
- innovative: 140
- initiative: 123
- technological: 120
- frontier: 118
- entrepreneur: 112
- advancement: 108
- project: 107
- engineer: 106
- sprint: 106
Bottom Words
- calm: -78
- silent: -81
- charming: -84
- myrtle: -85
- laughing: -85
- relax: -87
- silence: -87
- quiet: -90
- relaxation: -92
- sympathy: -102
Homer Jay Simpson
Top Words
- enjoying: 119
- neighborhood: 112
- relax: 103
- entertainment: 102
- enjoy: 102
- comfortable: 100
- comfort: 99
- lounge: 98
- cottage: 98
- friendly: 97
Bottom Words
- malpractice: -87
- leadership: -88
- pursuit: -90
- intelligence: -90
- investigation: -92
- studied: -92
- pursue: -94
- scholar: -97
- prophet: -99
- scientist: -100
The Joker (Batman)
Top Words
- dare: 108
- adventure: 107
- thriller: 90
- novelty: 89
- frontier: 88
- revolutionary: 87
- playboy: 87
- fantasy: 86
- unauthorized: 85
- deviant: 84
Bottom Words
- rest: -99
- maintenance: -100
- beneficial: -102
- comfort: -102
- quiet: -102
- calm: -103
- relax: -105
- relaxation: -113
- gently: -116
- gentle: -137
Check it out the word rankings for yourself (login required)
Notable Specific Careers
The top ranked specific careers are very interesting: (out of ~400 career options)
- Gollum - Taxidermist
- James Bond - Counterterrorism Analyst
- Elon Musk - Aerospace Engineer
- Trump - Political Campaign Manager
- Neil deGrasse Tyson and Captain Kirk - Astrobiologist
- Kanye West (198 - highest score) and Paris Hilton - Immersive Experience Director
- Darth Vader - Machine Ethics Advisor (Maybe if he survived at the end?)
- Cosmo Kramer and Marilyn Monroe - Improv Coach
- Arya Stark - Wildland Firefighter
- Ada Lovelace, Stephen Hawking, and Spock - Artificial Intelligence Ethicist
- Britney Spears - Music Therapist (I think this would be a great career move!)
- Captain Jack Sparrow - Underwater Archeologist
- Homer Jay Simpson and Michael Gary Scott - Stand-Up Comedian
- Vecna - Artificial Intelligence Ethicist (Seems like a very bad idea!)
- Tony Soprano - City Solicitor (Sounds about right...)
- Tony Stark - Augmented Reality Designer
- Anna Eleanor Roosevelt and Nelson Mandela - Human Rights Officer
- George Costanza - Cartoonist
- Cersei Lannister - Executive Pastry Chef (Stay out of her kitchen!)
- The Joker - Fashion Designer (Does the Joker have a clothing line?)
- The Rock - Sports Nutritionist
- Katniss Everdeen - Habitat Restoration Ecologist
Categorizing the Questions
I also played around with categorizing the questions and then only using questions from a category to create recommendation scores. For example one category is Food & Cuisine, then use this user embedding that only consists of choices made for Food & Cuisine questions for the recommendations for the Food category. It did seem to work better for some categories like food.
Similarity to Groups
I (actually GPT4 did it) tagged famous people with various labels in order to group them. For example Ada Lovelace was tagged with Historical Figure, Adult, Real Person, Female, Famous, Scientist, Author. This now creates grops of people and an average group embedding can be created by taking all of the members and averaging their user embeddings together element wise. This is the "Average Person" that shows up in the t-SNE chart and similiarity table. This group embedding now allows you to compare individuals to groups or groups to groups.
The General Personality rankings are for the ~160 famous people so a small and unique overall sample but the results are still interesting. There is also significant selection bias on which famous people were picked.
| Group | Realistic | Analytical | Creative | Philosophical | Assertive | Empathetic | Introverted | Optimistic | Adventurous | Extroverted |
|---|---|---|---|---|---|---|---|---|---|---|
| adults | 82 | 67 | 58 | 52 | 3 | -11 | -15 | -16 | -37 | -41 |
| child | 41 | 9 | 48 | 50 | -25 | 50 | 58 | -3 | 27 | 6 |
| males | 91 | 71 | 62 | 49 | -1 | -39 | -13 | -20 | -27 | -50 |
| females | 43 | 26 | 50 | 58 | -5 | 76 | 27 | 2 | -14 | 6 |
| fictionalCharacter | 75 | 39 | 73 | 30 | -1 | -3 | 8 | -10 | 37 | -8 |
| realPerson | 73 | 69 | 46 | 73 | -6 | 3 | -4 | -17 | -72 | -51 |
Write ups using LLMs
The ranked results for personality, careers, and similarity to famous people along with some basic profile questions (if you answer the questions you will see these - such as age, gender, hair color, etc...) are fed into the prompt along with instructions. We currently produce 6 reports: personality, career, matchmaking, dating profile, D&D Character, and Animal.
Images using DallE-3
The write up results from GPT4 are then fed into DallE-3 to produce an image based on the write up. It is really cool to see it go from answering some this or that questions, to a write up, to an image representing the person as an animal. This is one of my favorite animal images and I think it did an impressive job on Taylor Swift's animal:

Preview
Issues
Issues with Binary Choices, Poor Questions
The questions were created by GPT4 and despite some manual filtering still exhibit some biases toward certain opposite options and in many cases the opposites don't make entire sense. Being more aggressive in skipping questions does help. There also are alot of questions on environment, wellness, and tech. My guess is the poor question quality overall is why so many choices are needed (~500) to get the best results. Likely with better questions or a better method then just a binary choice, less questions would be needed. Also if you are targetting text embeddings from one specific category like clothing you can focus questions on that one area and will need many less questions.
Self-Reporting
Self-reflection can be hard. For real people it is likely to end up with results that are closer to who they want to be versus who they are. I come out extroverted but am definitely an introvert in most situations but I do wish I was more extroverted. The extrovert/introvert was one of the most confusing traits. It would be interesting to have a close friend/family member answer the questions for you and see how similar your user embedding is to your friend's version of your user embedding.
Issues with Famous People's Results
Having GPT4 generate the answers causes the results to be the general public perception of someone or better phrased as the general perception of the training data used. If the person was actually taking the test they would definitely have different answers for some of questions.
A great example of this is Cristiano Ronaldo's top personality trait is Vindictiveness. The exact embedded description is "A strong desire for revenge, which can fuel ongoing cycles of retaliation and escalate conflicts." It's rare for the top trait to be negative. It's fascinating that this happened since the questions are all fairly positive. If you look it up online there are a lot of stories about him being vindictive so somehow this made it into GPT4s answers for him and then showed up in the results. I doubt this would have happened if he actually answered the questions.
Ron Weasley from Harry Potter is another interesting one. A bigger Harry Potter fan then me should probably comment on this but it's fascinating that his top specific personality traits are opposite traits. I was unable to find another example as dramatic as his. The user embeddings appear to be able to handle the fact that you can be introverted and extroverted or in Ron's case he shows both Resentment and Munnanimity, Sensitivity and Insensitivity. It does make sense as in some situations (questions) one trait shows up and in other situations the opposite appears. This demonstrates the depth of knowledge held in the user embeddings.
Ron Weasley's Top 5 Specific Personality Traits (out of 149)
Further Research
Non-binary Choices and Weighted Averages
It would be easy to weight the decision based on the amount of time it took the user to make it. Quick decisions tend to be stronger feelings for a choice. Another option would be to figure out how to offer multiple choices or offer weighted choices such as Strong Left, Lean Left, No Choice, Lean Right, and Strong Right.
Supervised Learning with User Embeddings as Input
I think this has great potential. The user embeddings can be used as inputs to a Deep Learning Model and the target can be anything such as age, gender, or mental health issue. Once trained the model can then produce a probabilty or a number guess for someone not in the training set.
This or That Search (TOTS)
I think this would work well for certain areas such as clothing, hotels, dating sites. I could see online companies experimenting with this idea. Perhaps this might work better with image embeddings instead of text embeddings or perhaps combine text and image embeddings if possible.
Image Embeddings
I only used text embeddings but it would be just as easy to use embeddings that represent the image and then make the choice the difference of the image embeddings.